Update: If you are looking for Windows installation instead of Unraid, check out my new post here.
Looking for a self hosted AI chatbot service that can help with a wide range of tasks, including answering questions, brainstorming ideas, writing content, coding assistance, and much more. Chatbots like ChatGPT use a type of machine learning model called a large language model (LLM), which has been trained on vast amounts of text data and come in various sizes.
Ollama is a tool designed for running large language models (LLMs) locally on your computer. It simplifies the process of downloading, managing, and running open-source AI models without needing cloud access or complex configurations.
You can run Ollama as a docker container in Unraid. Then there is another docker service that is called open-webui that provides a front end webpage that looks very similar to ChatGPT. From there you can download various LLM and run them locally from within the docker service.
I will show how I configured docker to get the Ollama and the LLM’s installed and working.
First install the following docker services
- Ollama
- Open-webui
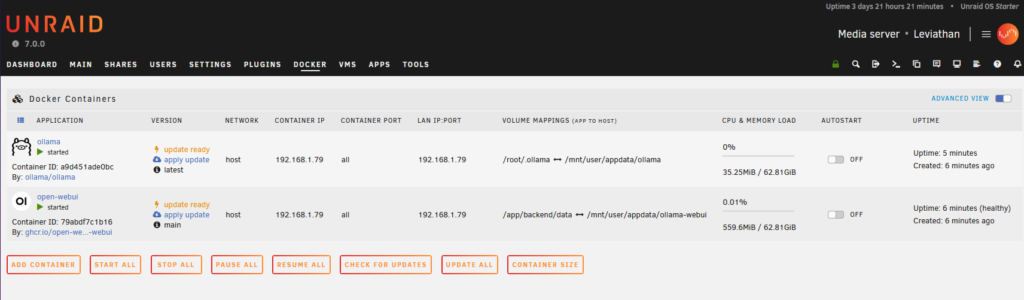
After they are installed you will need to make some small configure updates. I am still learning Unraid, so not sure if this is the best way, but should be suitable when running behind a firewall on a local server.
On the Ollama docker, I had to change 1 item and add 1 variable:
- Network type from “Bridge” to “Host”
- Add a variable “OLLAMA_HOST” with a value of 0.0.0.0. I believe this allows it to listen on any IP address.

On the open-webui I had to change 1 item
- Network type from “Bridge” to “Host”
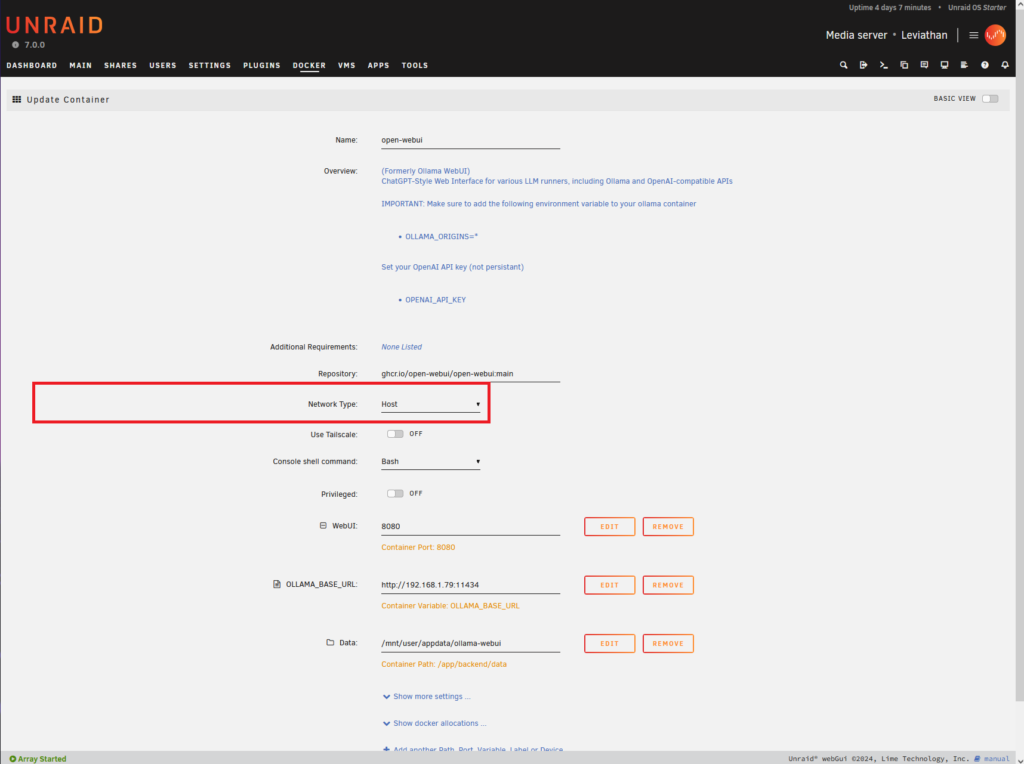
Almost done. Now you need to figure out what LLM you would like to install. Go to https://ollama.com/search and find a model you would like to try out.
Once you figure out what model you would like, from Unraid, on the docker image of Ollama, open up the Console and type in command of which model you would like
In this example, I decided to try out IBMs granite3.1-moe:1b model. When running the command “ollama run granite3.1-moe:1b“, if you do not have it downloaded, ollama will download it first then start it for you.

Now go back to Unraid docker and open up your “open-webui” container as WebUI. On the initial login it will ask you for a username and password. This is just for authentication with that docker instance, does not go out to the internet.
Now its time to start asking it questions. As you can see here I asked it “Tell me about Granite AI model”
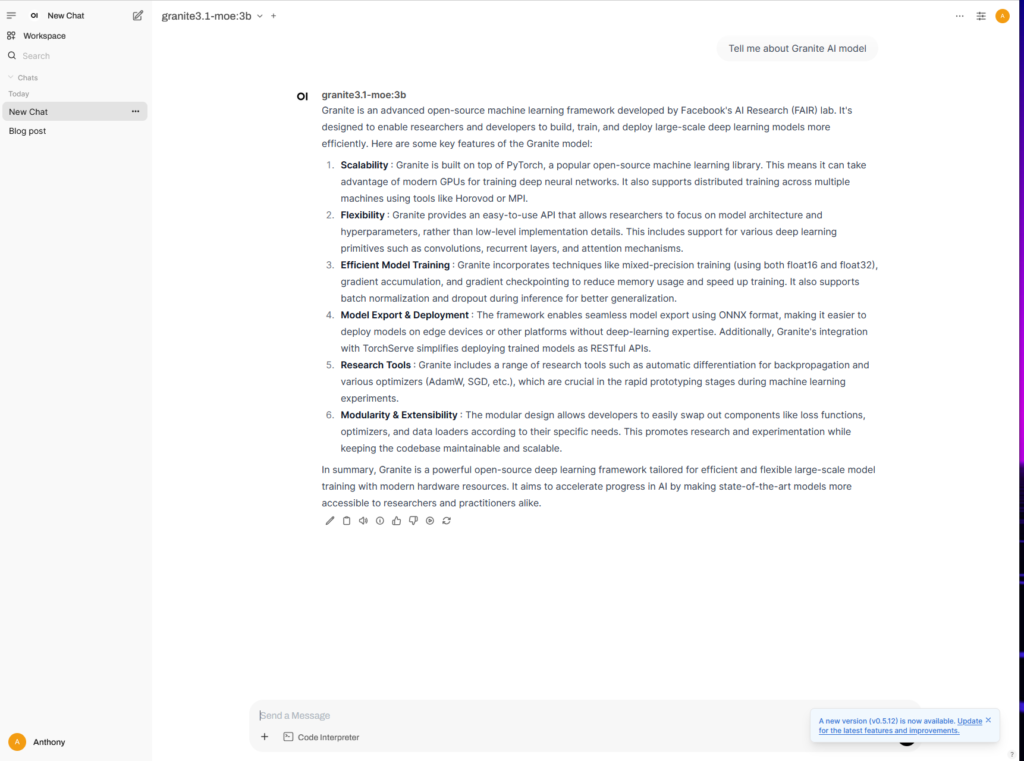
Congrats! You now have your own self hosted “ChatGPT” type of service. I’m running this service on a CPU-only instance. While it works using CPU only, using a GPU would significantly speed up response times due to the parallelized computing power GPUs offer. Using granite3.1-moe:3b, I would see response take from 10 to 30+ seconds (update: actually the 10 to 30 seconds was for very simple responses, most ended up being in the multiple minutes) range before it would start providing a response. I am sure using a powerful GPU would help speed up some of those answers. At the end of the day the tradeoff is worth it—you get full control, self-hosting capabilities, and the assurance that your data stays local.
I’m still fairly new to setting up this technology myself, so I’d love to hear about any tips or insights you’ve picked up along the way! What is your favorite LLM? Happy computing!
How did you get the ollama docker to run on unraid? Does it not require Nvidia gpu drivers to run?
When setting up ollama, turn on “advanced view” and I think it’s under “post arguments”, remove the gpu flag